The lab’s research program aims to explore and expand how advances in causal inference, statistical machine learning, and computational statistics catalyze discovery in the biomedical and public health sciences. Our methodological research emphasizes an assumption-lean, model-agnostic philosophy, taking a translational perspective that embraces the rich interplay between the applied sciences and the development of tailored statistical methods. Broadly, this approach draws upon causal inference principles to translate scientific questions into precise, interpretable statistical estimands, which one can then aim to learn from data generated by properly designed studies through the application of analytic methods that
- avoid imposing restrictions not justified by available domain knowledge;
- incorporate flexible, adaptive modeling strategies (e.g., machine learning); and
- apply semi-parametric efficiency theory for best-in-class uncertainty quantification.
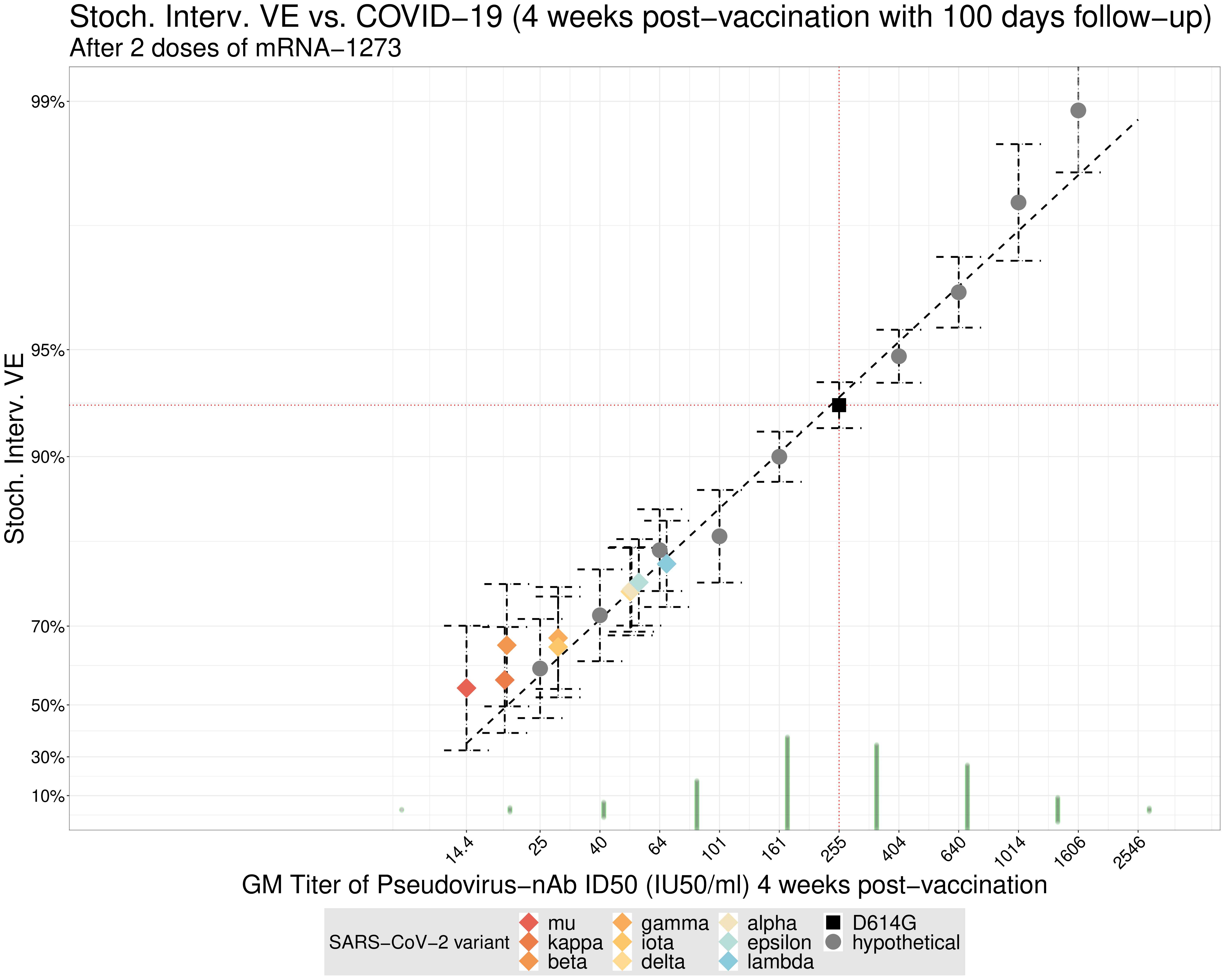
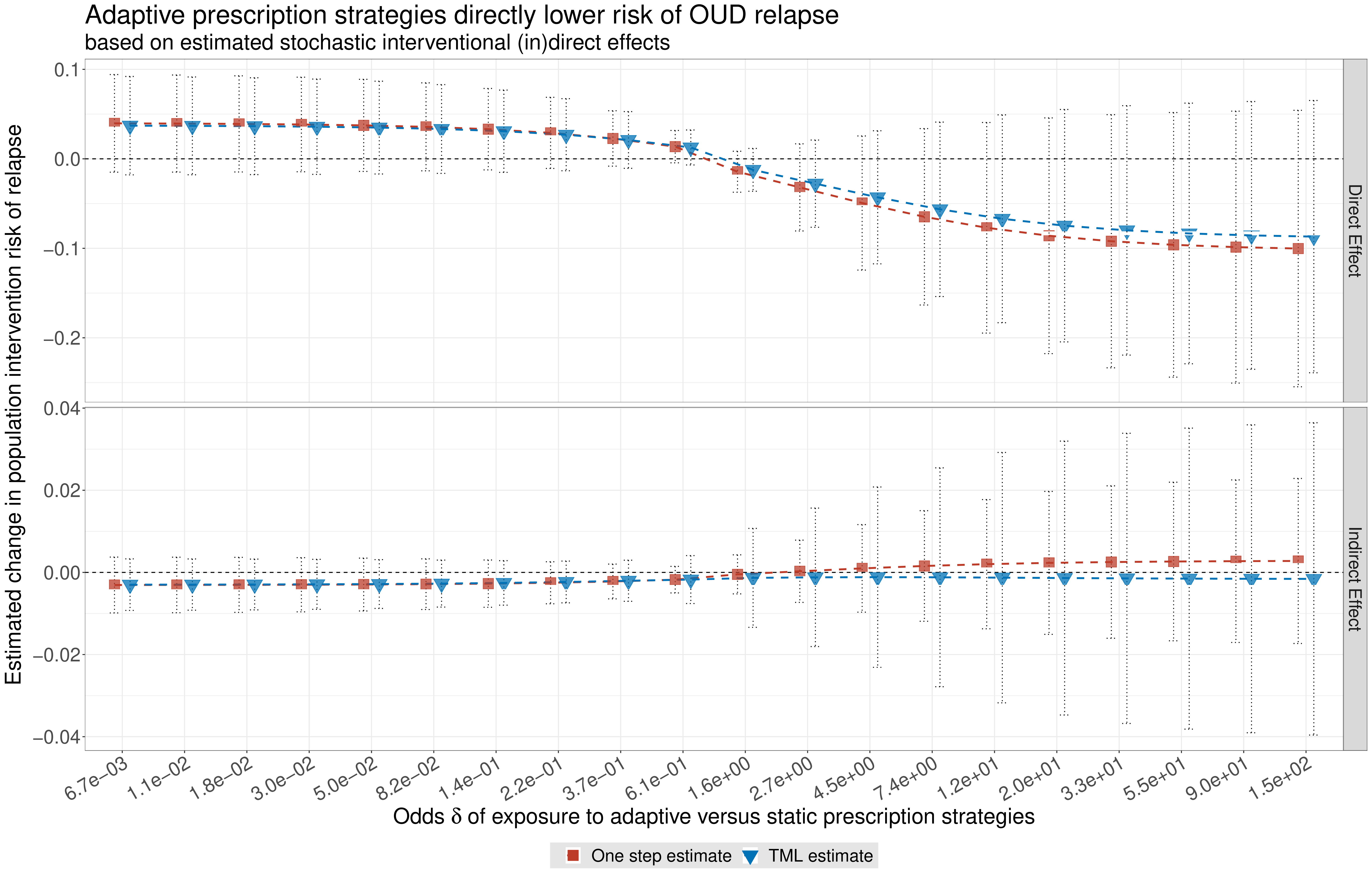
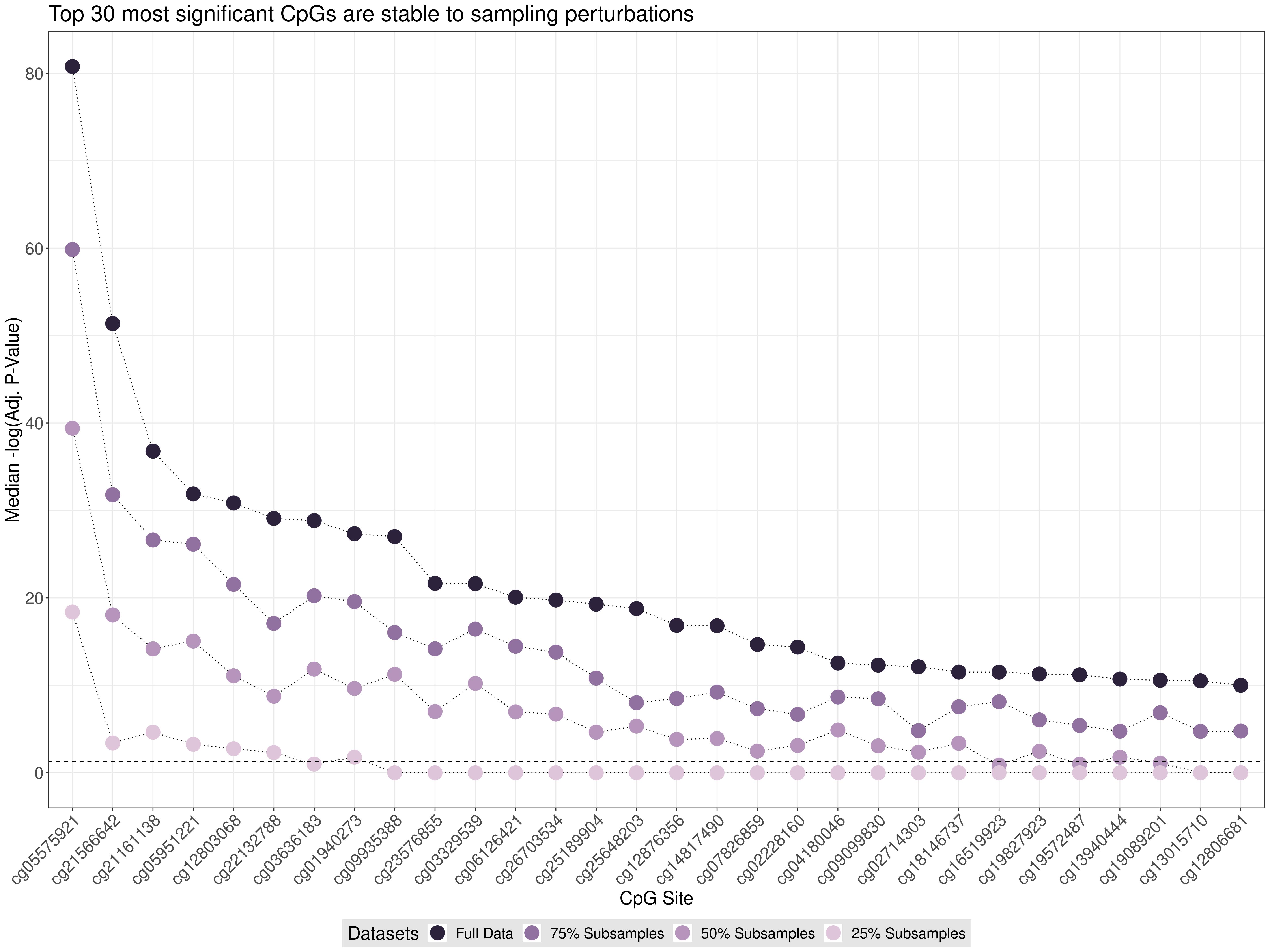
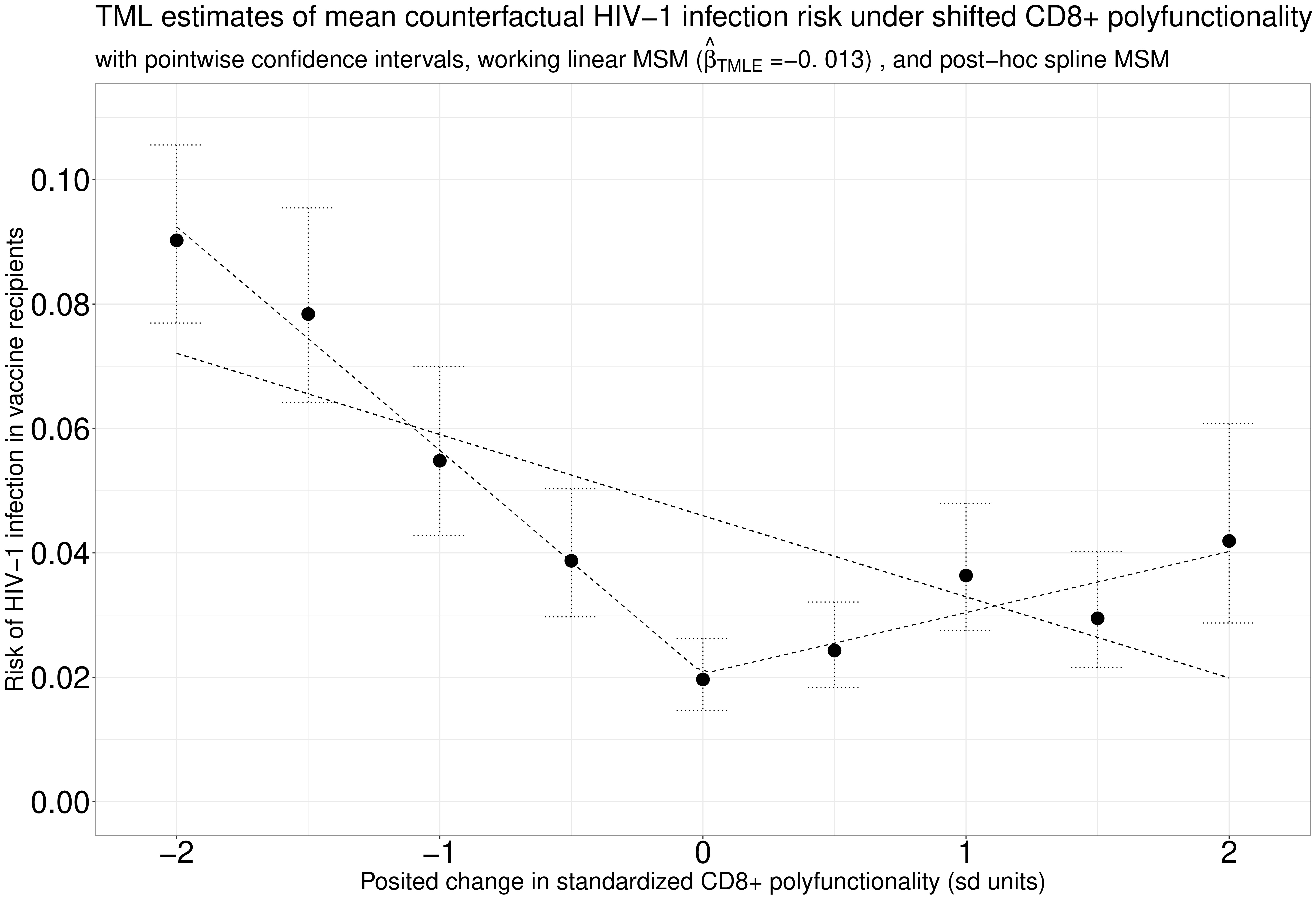
Thus, thematically, our research program integrates ideas from causal inference, to strive to target interpretable estimands, with tools and techniques from non-parametric estimation and statistical machine learning, to avoid restrictive modeling assumptions, while applying semi-parametric theory, to achieve asymptotically efficient estimation. This line of work has yielded novel insights applicable for causal (or de-biased or targeted) machine learning (e.g., targeted minimum loss estimation and sieve estimation); non-parametric causal mediation analysis to study questions of mechanism using novel direct and indirect effects; treatment effect heterogeneity and effect modification analyses to support stratified medicine; large-scale, variance-moderated semi-parametric estimation for flexible and stable biomarker discovery; corrections needed to reliably draw accurate inferences when data are collected using two-phase, auxiliary- or outcome-dependent sampling designs; and causal effect estimands for continuous exposures based on flexible intervention regimes.
We are often interested in and open to working in new substantive areas—wherever the application of rigorous statistical techniques and tools is welcome.
Here are a few highlights from research projects completed over the last few years:
A secondary theme of our research centers on the role of high-performance numerical computing and the development of open-source software tools for statistical science. While distinct, these areas are unified by the overarching aims of pushing the boundaries of statistical methods development and promoting reproducibility and transparency in the practice of applied statistics. Consistent with our commitment to open science, new methods developed by members of the lab are accompanied by open-source software implementations both to ensure replicability of the reported work and to facilitate widespread use of the proposed techniques.
Browse more about our work on statistical methods innovations, their use in applied sciences, and in developing free and open-source software for statistical science.